
Статья опубликована в рамках: XLIV Международной научно-практической конференции «Научное сообщество студентов XXI столетия. ТЕХНИЧЕСКИЕ НАУКИ» (Россия, г. Новосибирск, 26 июля 2016 г.)
Наука: Информационные технологии
Скачать книгу(-и): Сборник статей конференции
дипломов
ИЗВЛЕЧЕНИЕ МНЕНИЙ И ОБЪЕКТОВ МНЕНИЙ ИЗ ПОСТОВ СОЦИАЛЬНЫХ СИСТЕМ

Аннотация
В данной работе рассматривается проблема извлечения мнений из корпуса документов. Целью данной работы ставилось нахождение всех эмоциональных мнений об объектах предметной области из сообщений социальных систем. Предметной областью является тематика автосервисов и автодилеров. Для решения поставленной задачи использовался подход, основанный на тональных словарях. Была проведена оценка качества результата с помощью метрик полнота-точность
Введение
В повседневной жизни человек довольно часто сталкивается с проблемой выбора чего-либо в сфере, в которой он не имеет компетентных знаний. Если в недалеком прошлом мы обращались за традиционным советом к своим друзьям, близким, знакомым, то с бурным развитием информационно-вычислительных технологий и, в частности, глобальной паутины Интернет, для поиска необходимой информации и помощи в выборе чего-либо появилась достойная альтернатива.
Казалось бы, в век современных технологий что может быть проще, чем послать запрос поисковой машине, а она, в свою очередь, выдаст ответы на все вопросы пользователя. Однако из-за огромного количества разнообразного контента в мировом вебе, стремительно растущего с каждым днем, очень часто релевантная информация теряется среди мегабайт бесполезных данных. Вместе с этим, последнее десятилетие характеризуется ростом популярности различных социальных систем: блогов, форумов, социальных сетей, интернет-сервисов, аккумулирующих мнения о том или ином объекте. Ежедневно пользователи подобных ресурсов размещают множество сообщений, материалов, высказывают мнение о том или ином объекте. На основании подобных комментариев человек может сделать вывод о том, пользоваться или нет интересующей услугой, покупать или нет нужный продукт. На данный момент, несмотря на всю полезность такого подхода к мониторингу мнений, существует ряд серьезных недостатков: сложности в ручной обработке огромных объемов данных, нахождении мнений и их эмоциональной оценки, приведении результата к удобной форме.
Исходя из вышесказанного, появляется необходимость в создании системы автоматического нахождения и анализа мнений.
Постановка задачи
В качестве предметной области, представляющей входные данные, была выбрана тема автомобилей. А именно, имеется выборка постов, несущих, в большинстве своем, какую-либо эмоциональную окраску, с форума автолюбителей, где основными темами для обсуждения являются ремонт транспортных средств и их покупка/продажа.
Задача сентимент-анализа будет решаться с помощью словарного подхода. Она конкретизируется как: выделить все непосредственные мнения, относительно значимых в рамках данной тематики объектов, удовлетворяющие информационную потребность пользователя. Другими словами, имеется запрос пользователя, представленный текстовой строкой. Итоговым результатом будет являться набор кортежей (объект, полярность мнения об объекте, содержащий объект пост), релевантных запросу.
Анализ предметной области
Задача поиска и анализа мнений ставится в дисциплине, которая находится на стыке информационного поиска и компьютерной лингивистики - анализ тональности текста и извлечение мнений (англ. sentiment analysis & opinion mining, также употребим термин сентимент-анализ). Сентимент-анализ - система автоматического получения из текстов эмоционально окрашенной лексики и мнений по отношению к объектам, речь о которых идет в тексте. В работе [4] осуществляется один из первых полных обзоров всей области, связанной с исследованием мнений. Здесь затрагиваются темы определения тональностей, выделения мнений, сложностей связанных с анализом сравнительных предложений, поиска спама в мнениях.
Для задачи извлечения мнений главной целью является нахождение в тексте всех эмоционально окрашенных мнений относительно чего-либо. Под мнением понимается эмоциональное суждение о какой-либо сущности или ее аспекте, высказанных неким субъектом. В целом, мнение может быть выражено в отношении любого предмета: продукта, услуги, персоны, организации, события и т.п. Для того чтобы выделить сущность, о которой идет речь в тексте, используется термин объект.
Мнения бывают двух видов: непосредственные мнения и сравнения. Их общая модели мнения приводятся в [3]. Ключевым понятием здесь является полярность мнения. Полярность мнения в задачах сентимент анализа выражается с помощью лексических тональностей (лексических сентиментов, слова-сентименты) - эмоциональных составляющих, выраженных на уровне лексемы.
Проектирование системы извлечения мнений
Первоначальная обработка
Для обеспечения удовлетворительного результата нужно провести преобработку корпуса документов. Для этого для каждого документа из корпуса выполняются процедуры токенизации; нормализации и стемминга для полученных лексем. Подобный разбор был проведен при использовании технологии Mystem [2] от Yandex.
Построение объектных категорий
Просматривается выборка постов из корпуса. В процессе просмотра выполняется поиск лексем, являющихся релевантными для удовлетворения типичной информационной потребности пользователя в рамках данной тематики.
Как релевантные были определены лексемы, относящиеся к тематике автосервисов, автодилеров, обслуживающего персонала этих заведений; покупки, продажи, ремонта автомобилей; техобслуживания и автозапчастей.
При нахождении новой лексемы, удовлетворяющей выше сказанным требованиям, проверяется, существует ли категория, логически правильно описывающая данную лексему. Если да, то пополняется список слов, характеризующих данную категорию, добавлением в него текущей лексемы.
Если же подходящая категория не обнаружена, то создается новая. Для этого подбирается слово, наиболее полно описывающее ту область, к которой относится лексема. После этого лексема добавляется в список слов данной новой категории.
Пополнение объектных категорий:
Полученные в прошлом разделе категории достаточно скудны по своему объему. Необходимо пополнить их, воспользовавшись алгоритмами для получения слов-синонимов. Для того чтобы расширить начальные категории, нужно получить список синонимов для каждого из слов-объектов, попавших в исходные категории.
В качестве выбранного метода для построения списков синонимов была выбрана технология word2vec. В результате построенная модель будет иметь структуру таблицы ключ-значение, где в качестве ключа выступает лексема, для которой нужно найти синонимы, а значение - массив пар лексема:значение близости между данной лексемой и лексемой-ключом.
Пополнение начальных категорий осуществляется нехитрым образом: выполняется обход по всем лексемам начальной категории. Для каждого объекта ищется соответствие лексеме-ключу из таблицы. Если соответствие найдено, то исходная категория пополняется лексемами из массива значений.
Построение тональных словарей
При использовании словарного подхода ключевую роль играет использование тональных словарей. Для этой работы был составлен тональный словарь, основанный на классификации сентиментов по бинарной шкале, т.е слова-сентименты имеют значение либо 1, либо -1.
Общий алгоритм:
- Построение начальных объектных категорий, их расширение с помощью списка синонимов, создание тонального словаря, предобработка начальной коллекции.
- Пользователь подает на вход, интересующий его запрос. Данный запрос разбивается на лексемы.
- Для каждой полученной лексемы выполняется поиск по списку расширенных объектных категорий. Если найдено соответствие исходной лексемы и какой-либо лексемы из списка, то расширенная объектная категория помечается как релевантная.
- Проведение обхода по корпусу документов. Если найдена лексема из помеченных в п.2 категорий, то осуществляется просмотр n-граммы, относящейся к найденному объекту.
- Если в n-грамме находится слово-сентимент из тонального словаря, то помечаются объект, слово-сентимент и сам пост. Если слов-сентимент найдено несколько, то берется ближайшее из них. Определяется полярность этого сентимента. Объекты, не имеющие в своей n-грамме слово-сентимент не попадают в итоговую выдачу.
- Вывод полученных данных: пост, в котором обнаружено мнение, и само мнение - кортеж (объект, полярность мнения об объекте, содержащий объект пост).
Реализация системы
Для реализации системы сентимент-анализа был выбран язык программирования Java. Ее создание проходило в среде разработки IntelliJ IDEA 15.0.4.
Для получения объектных категорий система использует выборку, построенную на основании 150 постов. В этой выборке были выделены 27 объектных категорий. Каждая их этих категорий до пополнения синонимами насчитывает в среднем 5-6 объектов.
В рабочем режиме система использует тональный словарь, содержащий 200 слов-сентиментов, полученных из 1034 отдельно отобранных постов. В нем содержится 114 слов с оценкой «1» и 86 с оценкой «-1».
Кроме того, для построения синонимов использовалась обученная с помощью технологии word2vec готовая модель [1]. Список синонимов содержит более 1000000 записей, в каждой из которых лексеме-ключу ставится в соответствие массив от 2 до 100 лексем, имеющих наибольшее значение близости с лексемой-ключом.
Оценка качества
В настоящее время не существует объективных методов оценки качества сентимент-анализа текстов. Поэтому обычно применяется тестирование, основанное на субъективных оценках экспертов. Вариантом такого тестирования является получение стандартных метрик полноты и точности.
Для оценки качества работы разработанной системы построена тестовая выборка из 1500 оригинальных постов. В рамках данной выборки находились значимые в рамках выбранной тематики лексемы (процесс аналогичен построению объектных категорий). Если такая лексема была найдена, и для нее могла была определена полярность тональности, то кортеж (лексема; полярность; пост, откуда была выделена лексема) помещался в класс для оценки тональности. Затем для этого класса и результатов работы программы по извлечению мнений из тестовой выборки считались метрики.
Кроме вышесказанного, для анализа того, насколько сильно влияет на итоговый результат построение тональных словарей, начальных категорий и списков синонимов были созданы альтернативные начальные выборки. Так для исследования влияния построения начальных категорий было создано 5 выборок: 3 выборки по 50 постов для оценки влияния качественного изменения начальных категорий, выборки по 100 и 150 постов для анализа того, что происходит при увеличении числа постов. Аналогичные структуры данных были построены для словаря тональностей (словари объемом 50, 100 и 200 наименований), списка синонимов (100000, 500000 и 1000000 записей).
Для задачи извлечения мнений посчитаны следующие метрики:


Рис.1 Метрики качества при изменении качественного и количественного состава выборки постов для построения объектных категорий


Рис.2 Метрики качества при изменении количества записей в тональном словаре

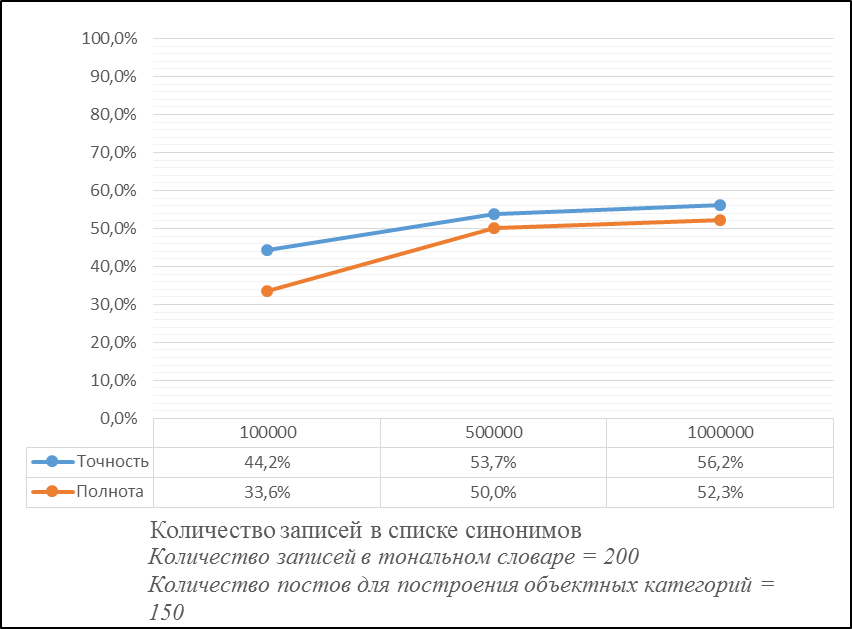
Рис.3 Метрики качества при изменении количества записей в списке синонимов
Из рис. 1-3 видно, что изменения качества постов для построения объектных категорий не приводят к значительному изменению результата. Напротив, увеличение объемов исходной выборки дает улучшение результатов вплоть до 15%.
Выводы
Результатом данной работы является реализация программного компонента, извлекающего мнения из сообщений социальных систем.
Для построенной системы была проведена оценка качества работы системы на основании подсчета метрик точности и полноты. Стоит заметить, что изменение качественного состава исходных выборок не так сильно влияет на результат, как изменение их количественных характеристик. Оценки качества показывают, что чем больше исходные вспомогательные коллекции, тем корректнее система определяет тональность документов и выделяет из них мнения. Следовательно, решения, использующие словарный подход, нуждаются в постоянной поддержке экспертами, а масштабирование вспомогательных коллекций идет на пользу данным системам. Наиболее очевидным способом улучшения разработанной системы является добавление к тональному подходу правил, основанных на морфологическом разборе
Список литературы
- Русскоязычные W2V модели – [электронный ресурс] – Режим доступа. – URL: http://panchenko.me/rsr/ (дата обращения: 12.03.2016)
- Сайт технологии Yandex Mystem, выполняющей морфологический разбор текстов на русском языке – [электронный ресурс] – Режим доступа. – URL: https://tech.yandex.ru/mystem/ (дата обращения: 01.03.2016)
- Liu. B. Sentiment Analysis and Subjectivity // In N. Indurkhya & F. J. Damerau. (Eds.). 2010.
- Liu, B. Web Data Mining // Springer. 2007. P. 433.
дипломов
Оставить комментарий